Building Clean, Maintainable vLLM Modifications Using the Plugin System
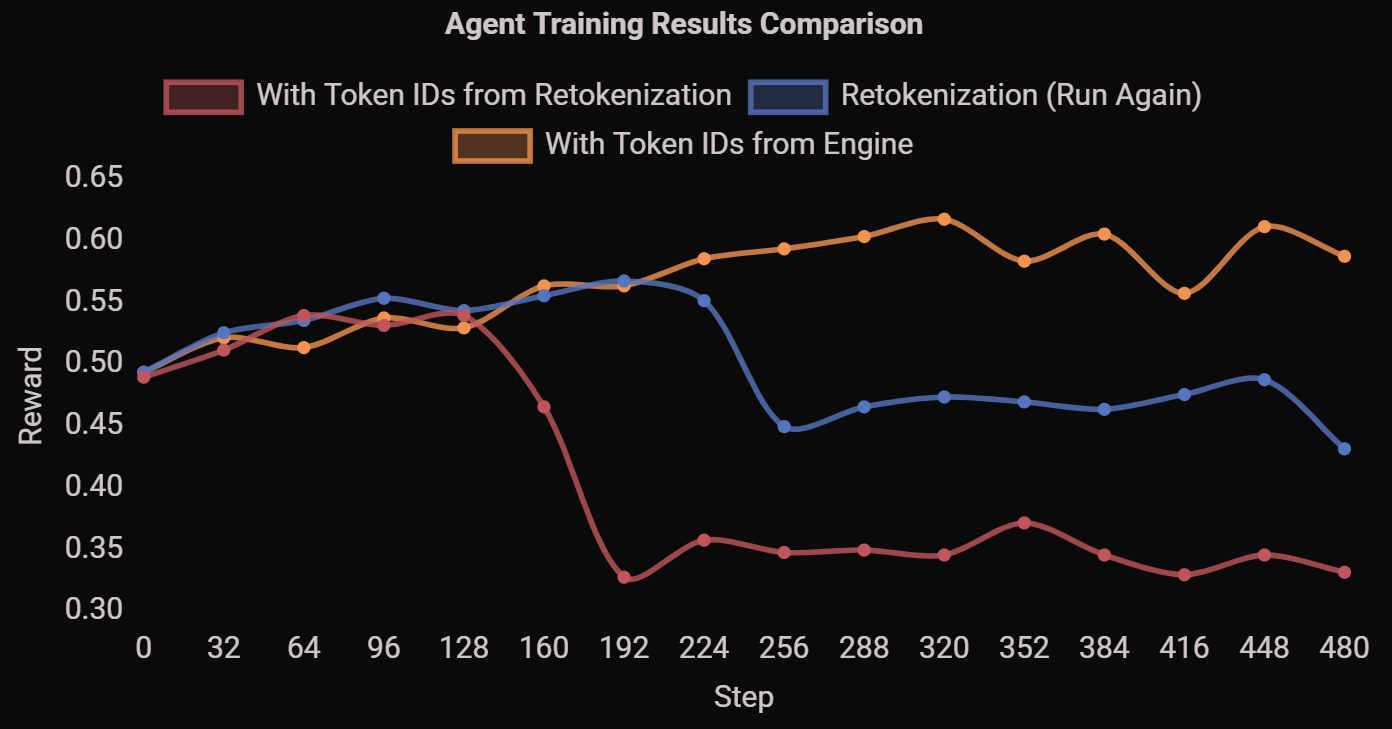
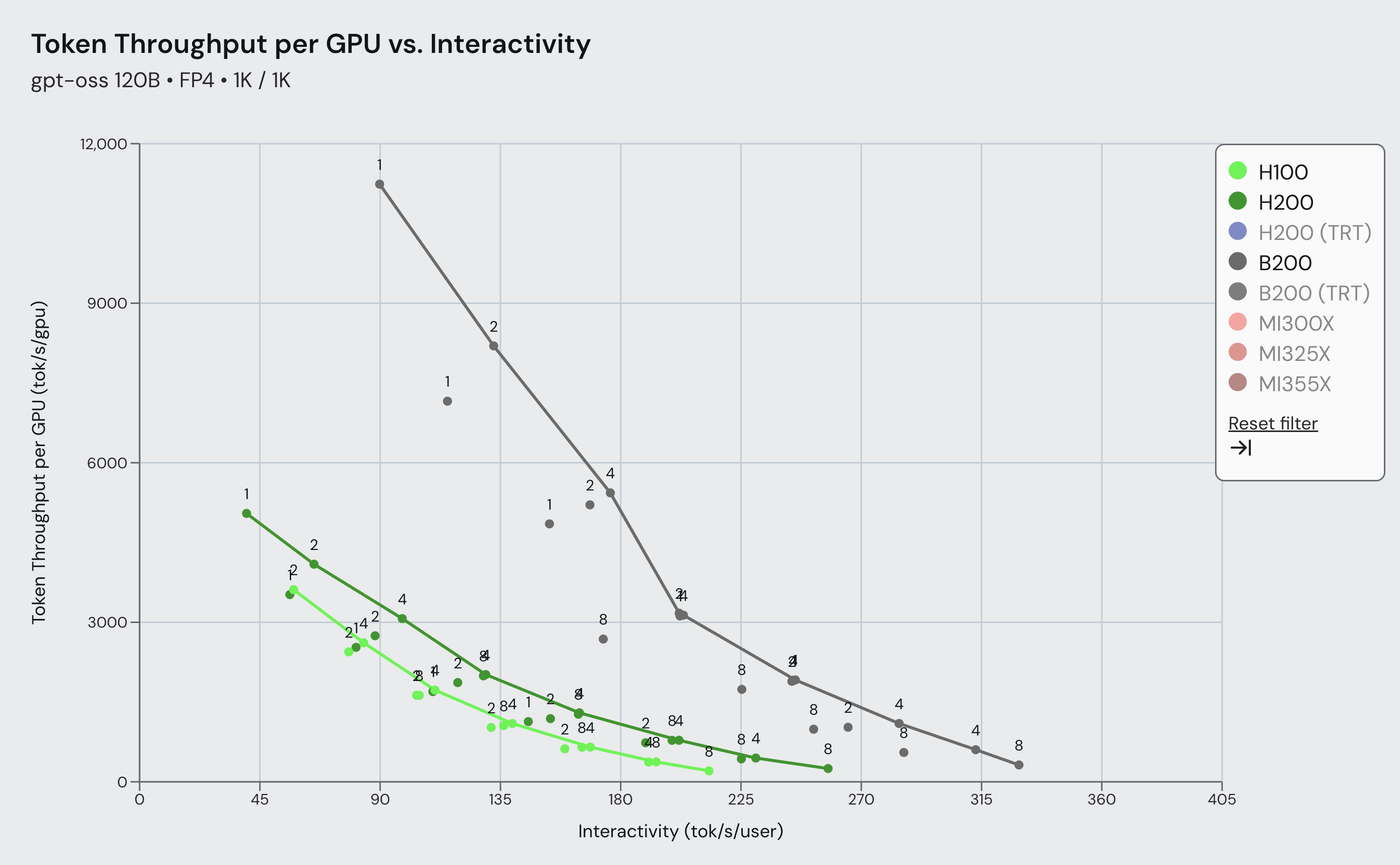
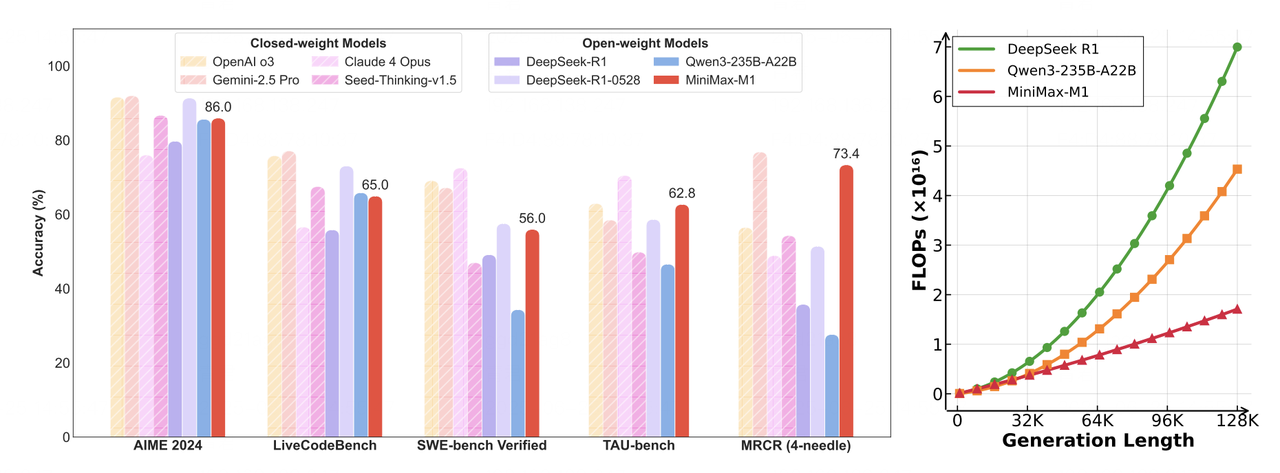
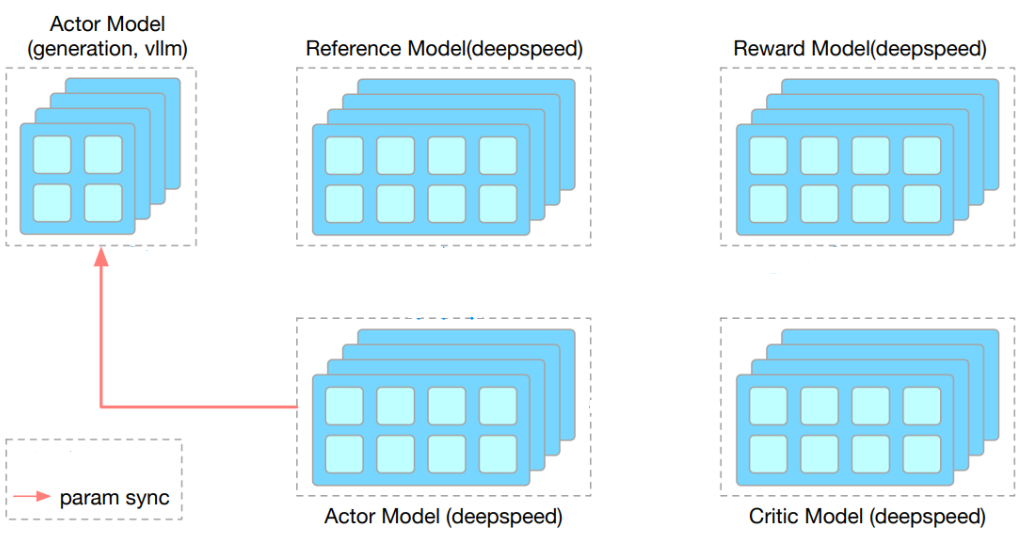
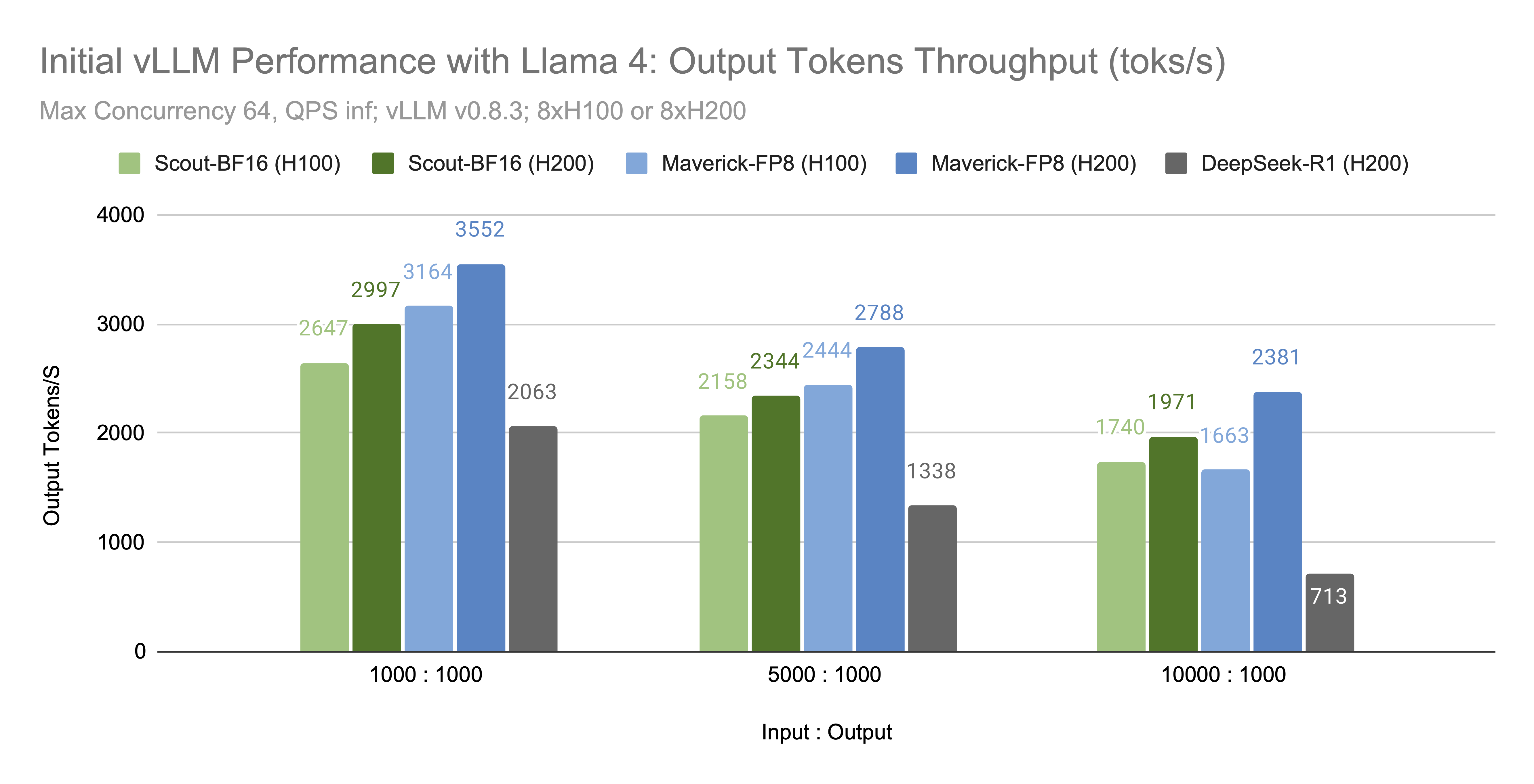
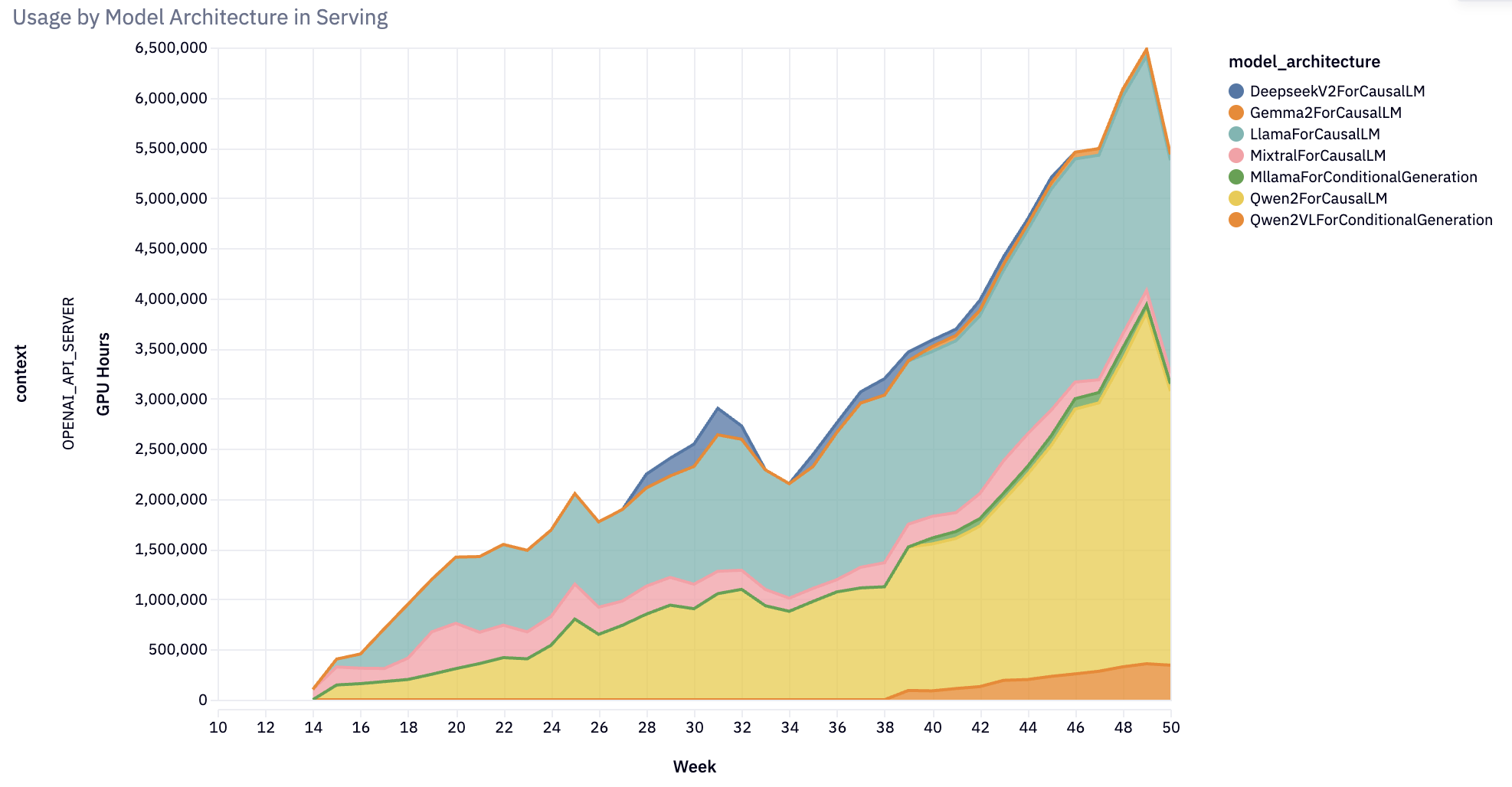
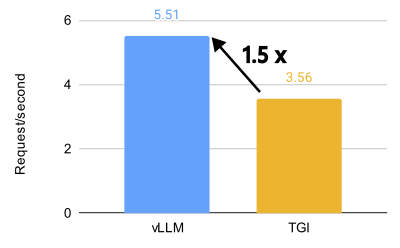
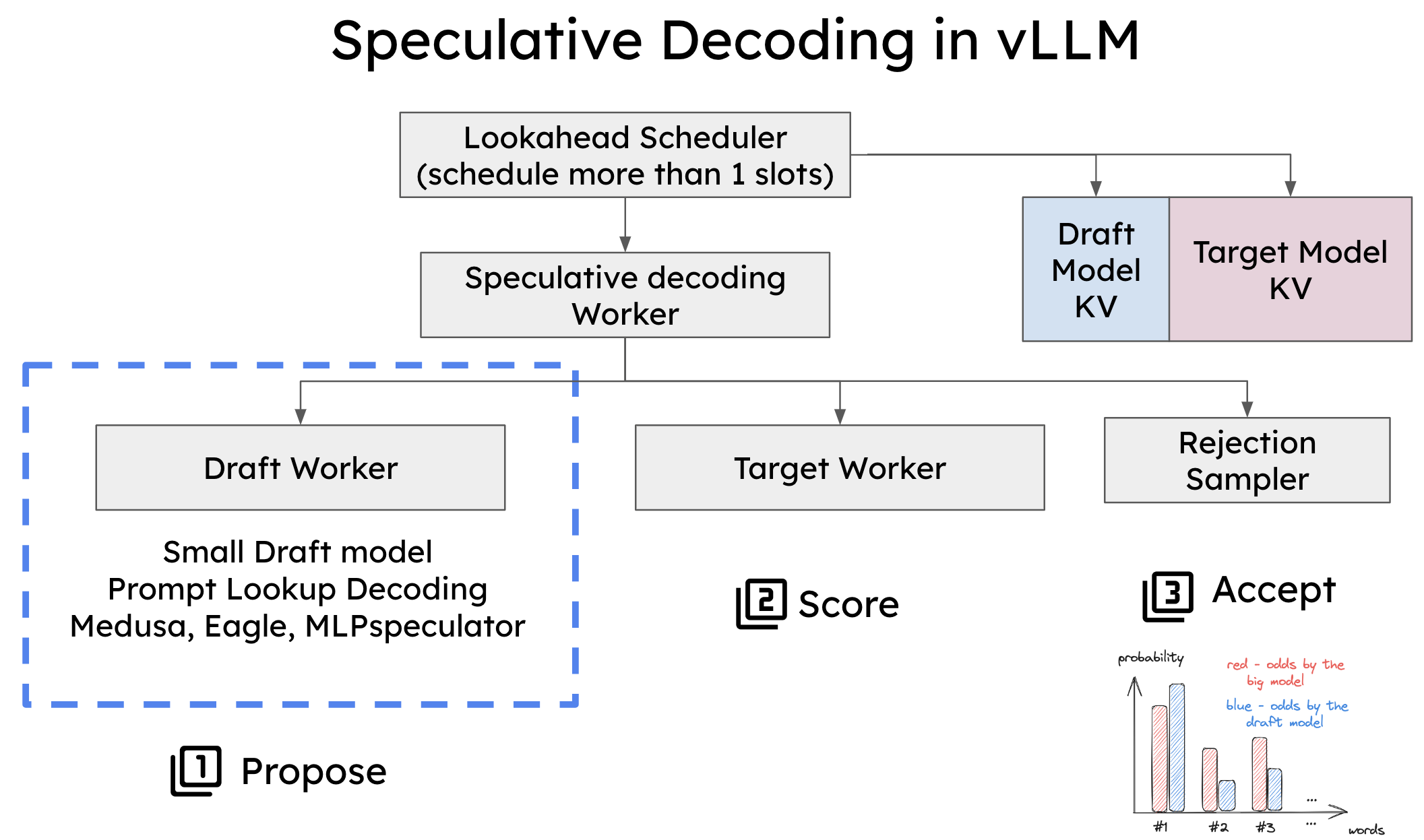
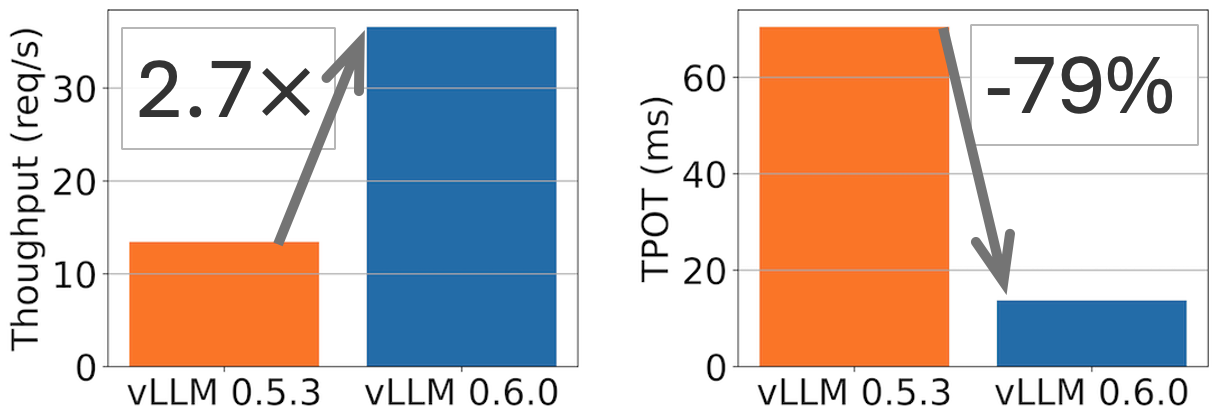
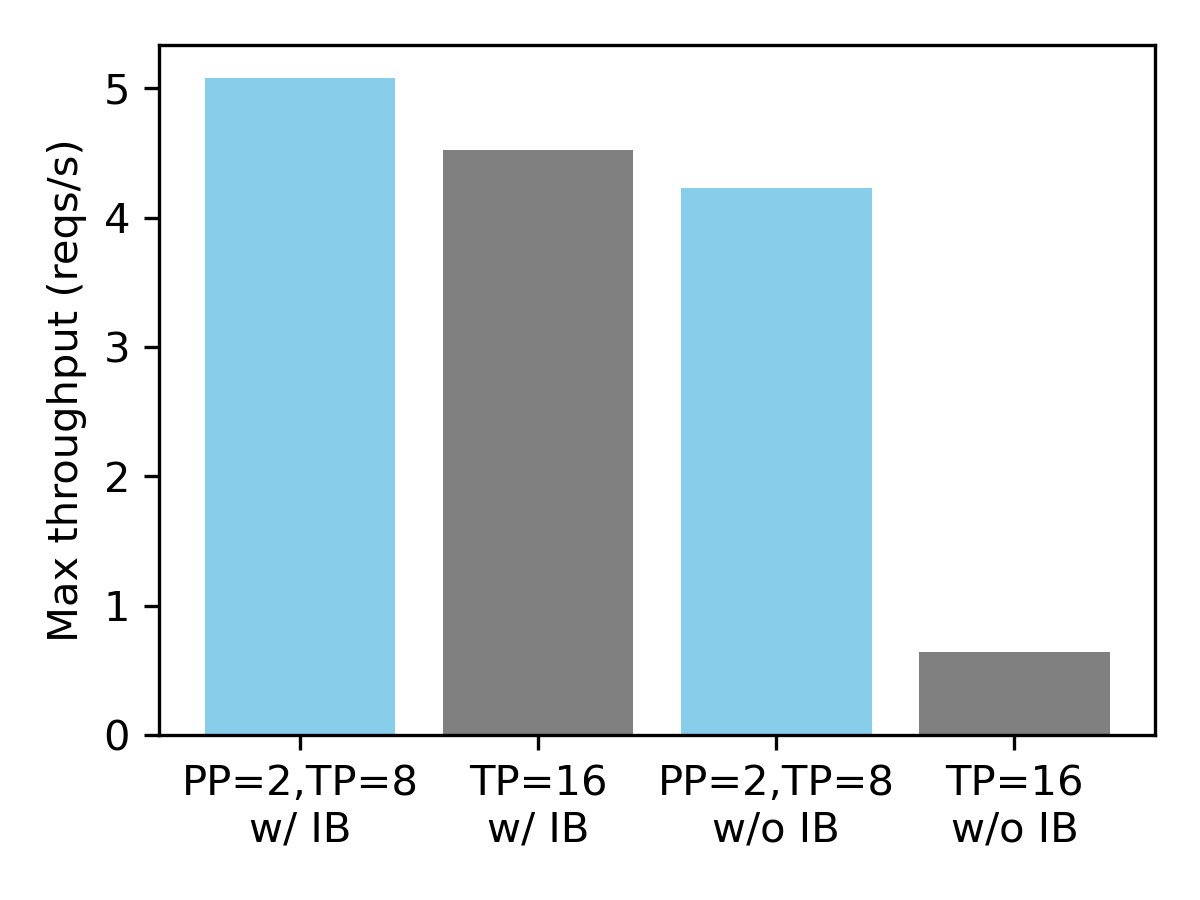
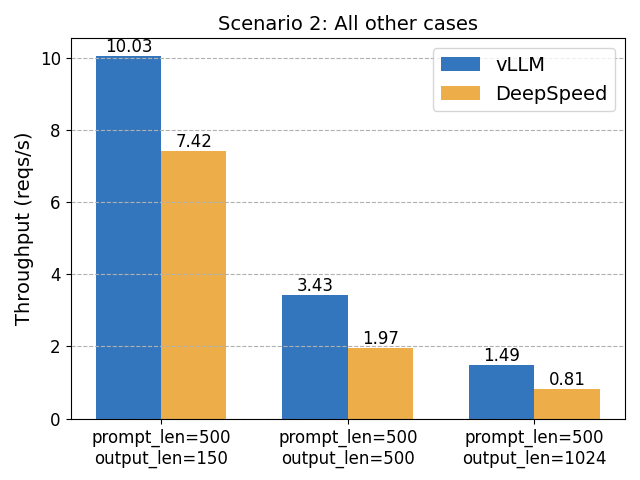
[!NOTE] Originally posted on this Medium article. Source: https://github.com/vllm-project/vllm-ascend Avoiding forks, avoiding monkey patches, and keeping sanity intact Overview Large Language Model inference has been...