Industry Status: Inference ≠ More Is Better
Over the past year, hybrid reasoning and automatic routing have increasingly defined progress in large-model infrastructure—shifting the debate from raw scale to per-token efficiency, latency control, and targeted compute use.
Take GPT-5 for example: its standout innovation lies not in sheer parameters, but in routing policies and quota-based reasoning:
- Light queries → lightweight paths: trivial prompts like “Why is the sky blue?” don’t trigger expensive reasoning.
- Complex/high-value queries → reasoning-enabled models: multi-step tasks—like legal analysis or financial planning—are routed to Chain-of-Thought–enabled inference.
This represents a broader principle of task-aware compute allocation, where every inference token must contribute meaningful value—not just be consumed.
Similar ideas are appearing in other systems:
- Anthropic Claude 3.7/4: differentiates “fast thinking” and “slow thinking” pathways.
- Google Gemini 2.5: offers explicit thinking budgets, allowing enterprises to cap reasoning depth.
- Alibaba Qwen3: supports instruction-driven switching between reasoning and non-reasoning modes.
- DeepSeek v3.1: merges conversational and reasoning flows within a dual-mode single model.
The trend is clear: future inference systems will be defined by selectivity and intelligence, not just model size.
Recent Research: vLLM Semantic Router
Responding to this shift, the vLLM Semantic Router offers an open-source, intent-aware routing layer for the highly efficient vLLM inference engine.
vLLM enables scalable LLM serving—but lacks semantic decision-making around reasoning. Developers face a trade-off:
- Enable reasoning always → accuracy increases, but so does cost.
- Disable reasoning → cost drops, but accuracy suffers on complex tasks.
The Semantic Router fills this gap by classifying queries semantically and routing them appropriately, giving accurate results where needed and efficiency where reasoning is unnecessary.
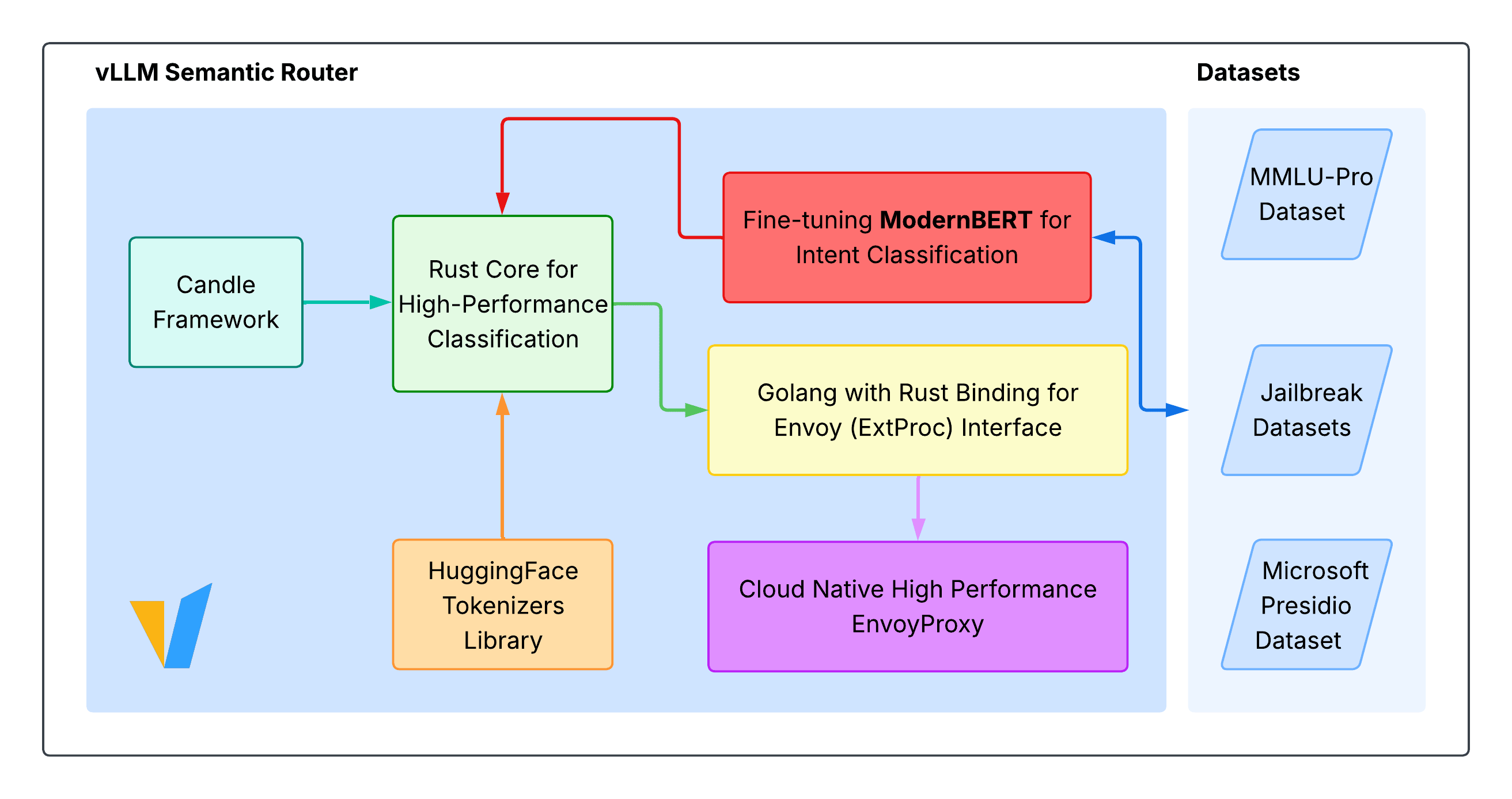
Architecture Design
The system comprises four pillars:
- Semantic Classification: Uses ModernBERT—currently a lightweight, standalone classifier integrated into the router—to determine routing paths.
- Smart Routing:
- Simple queries → “fast path” inference.
- Complex queries → “Chain-of-Thought” reasoning mode.
- High-Performance Engine: Written in Rust using Hugging Face Candle, it delivers high concurrency and zero-copy inference.
- Cloud-Native Integration: Works out-of-the-box with Kubernetes and Envoy via the
ext_procplugin.
In trials, this design yielded:
- ~10% higher accuracy
- ~50% lower latency
- ~50% fewer tokens
In business and economics domains, gains exceeded 20% accuracy improvements.
Challenges in Execution: Budgets and Tool Calling
Two technical constraints are important to address:
- Reasoning Budget Costs
Unlimited reasoning inflates cold-start latency and resource usage. Without dynamic control, simple queries may over-consume tokens while critical queries may not get deep reasoning when needed. SLOs like TTFT and p95 latency are necessary—with possible adaptation mid-inference. - Tool Calling Constraints
Adding more tools (i.e. “tool catalog bloat”) or longer tool outputs can drastically reduce accuracy. The router must pre-filter tools and keep catalogs tight.
Project Background
The Semantic Router evolved from contributions across the open-source community:
- Proposed in early 2025 by Dr. Chen Huamin (Red Hat)
- Further developed by Xunzhuo Liu (Tencent)
- To be presented by Dr. Wang Chen (IBM Research) and Dr. Chen Huamin at KubeCon North America 2025
Our goal: provide inference acceleration for open-source LLMs through:
- Semantic-aware routing
- Efficient model switching
- Enterprise-friendly deployment (Kubernetes & Envoy)
Find the project on GitHub. The current focus is on a Work Group and planned v0.1 Roadmap.
Integration & Future Work: Embeddings and Pluggability
Currently, ModernBERT runs internally within the router for classification. It is not yet served by vLLM. However, future work aims to make the classifier—and potentially other embedding models—pluggable, allowing integration with vLLM-hosted models or external embedding services.
This capability will enhance the semantic cache and enable smoother inference customization.
Roadmap: v0.1 Milestone Highlights
The v0.1 milestone will expand the project’s technical capabilities:
- Core: ExtProc-based modularity, semantic caching across backends, multi-factor routing logic
- Benchmarking: CLI tools, performance testing suite, reasoning-mode evaluation
- Networking: Deeper integration with Envoy, GIE, and llm-d gateways
- Observability & UX: Admin dashboards, routing policy visualization, developer quickstarts, and policy cookbook
Future Trends: Just-in-Time Inference
The field is maturing from “Can we run inference?” to “How can inference be smarter?”
- GPT-5 uses commercial value to guide reasoning depth.
- vLLM Semantic Router delivers that capability to open source.
Looking ahead, systems that adapt their inference strategy on the fly, without manual toggles, will lead in efficiency, latency, and sustainability.
One-Sentence Summary
- GPT-5: enterprise routing for smarter inference
- vLLM Semantic Router: technical-first routing for open-source LLMs
- Edge future: context-aware, minimal-compute inference that works seamlessly