Introduction
Over the past several months, we’ve been collaborating closely with NVIDIA to unlock the full potential of their latest NVIDIA Blackwell GPU architecture (B200/GB200) for large language model inference using vLLM. Blackwell GPUs introduce a new class of performance and efficiency improvements, such as increased memory bandwidth and native FP4 tensor cores, opening exciting opportunities to accelerate inference workloads.
Blackwell delivers great performance out of the box, but to extract even more from the hardware, our joint optimizations refactored existing kernels and developed new ones tailored for lower-level hardware utilization, unlocking additional performance and improved efficiencies. The new SemiAnalysis InferenceMAX benchmarks reflect these enhancements, demonstrating outstanding vLLM performance on Blackwell with up to 4x higher throughput at similar latency compared to previous-generation Hopper GPUs on popular models, such as gpt-oss 120B and Llama 3.3 70B.
This effort was a multi-month engineering collaboration involving over a hundred pull requests across the vLLM codebase. Together with NVIDIA, we optimized nearly every part of the inference pipeline - from custom kernels (attention, GEMM, MoE) to high-level scheduling and overhead removal. This blog provides a detailed breakdown of these optimizations and how they leverage Blackwell’s architectural features into production performance gains.
Overview of InferenceMax
SemiAnalysis InferenceMax is a benchmark framework designed for automated, recurring tests on LLM serving performance, with results updated daily to reflect software performance changes. This approach narrows the gap between software updates and published benchmark data, using consistent test methodologies to ensure fair, reproducible comparisons.
InferenceMAX currently evaluates vLLM with two representative open-source models:
- Mixture-of-Experts (MoE) : gpt-oss 120B
- Dense : Llama 3.3 70B
To simulate real-world usage, the benchmark runs each model under a variety of prompt/response length scenarios (ISL = input sequence length, OSL = output sequence length). Specifically, tests cover three regimes:
- 1K ISL / 1K OSL (chat, moderate input/output)
- 1K ISL / 8K OSL (reasoning, long outputs)
- 8K ISL / 1K OSL (summarization, long inputs)
Delivering Performance Across the Pareto Frontier
Blackwell’s new compute architecture delivers a step-change in inference efficiency, incorporating the latest HBM3e memory (192 GB of HBM3e at 8 TB/s per B200), high NVLink data transfer speeds (1.8 TB/s per GPU) and built-in support for FP4 precision format with 5th generation tensor cores.
By adapting our kernels to fully exploit these advances, we’ve seen dramatic gains in throughput (per-GPU performance) and responsiveness (per-request latency) compared to running vLLM on the prior Hopper architecture.
Modern inference workloads vary widely in sequence length, batch size, and concurrency. A configuration that yields highest throughput often isn’t the one that gives lowest latency per user. Thus, single-point metrics can be misleading. SemiAnalysis InferenceMAX applies a Pareto frontier methodology to evaluate the trade-off between responsiveness and throughput, mapping Blackwell’s performance envelope across real-world operating conditions.
Our primary goal in our collaboration with NVIDIA has been to ensure that vLLM leverages Blackwell’s features to deliver great performance across the full Pareto frontier.
We’re excited to see that the SemiAnalysis benchmark results show consistent vLLM performance improvements with Blackwell compared to the prior generation Hopper architecture across all interactivity levels for both the gpt-oss 120B and Llama 3.3 70B models.
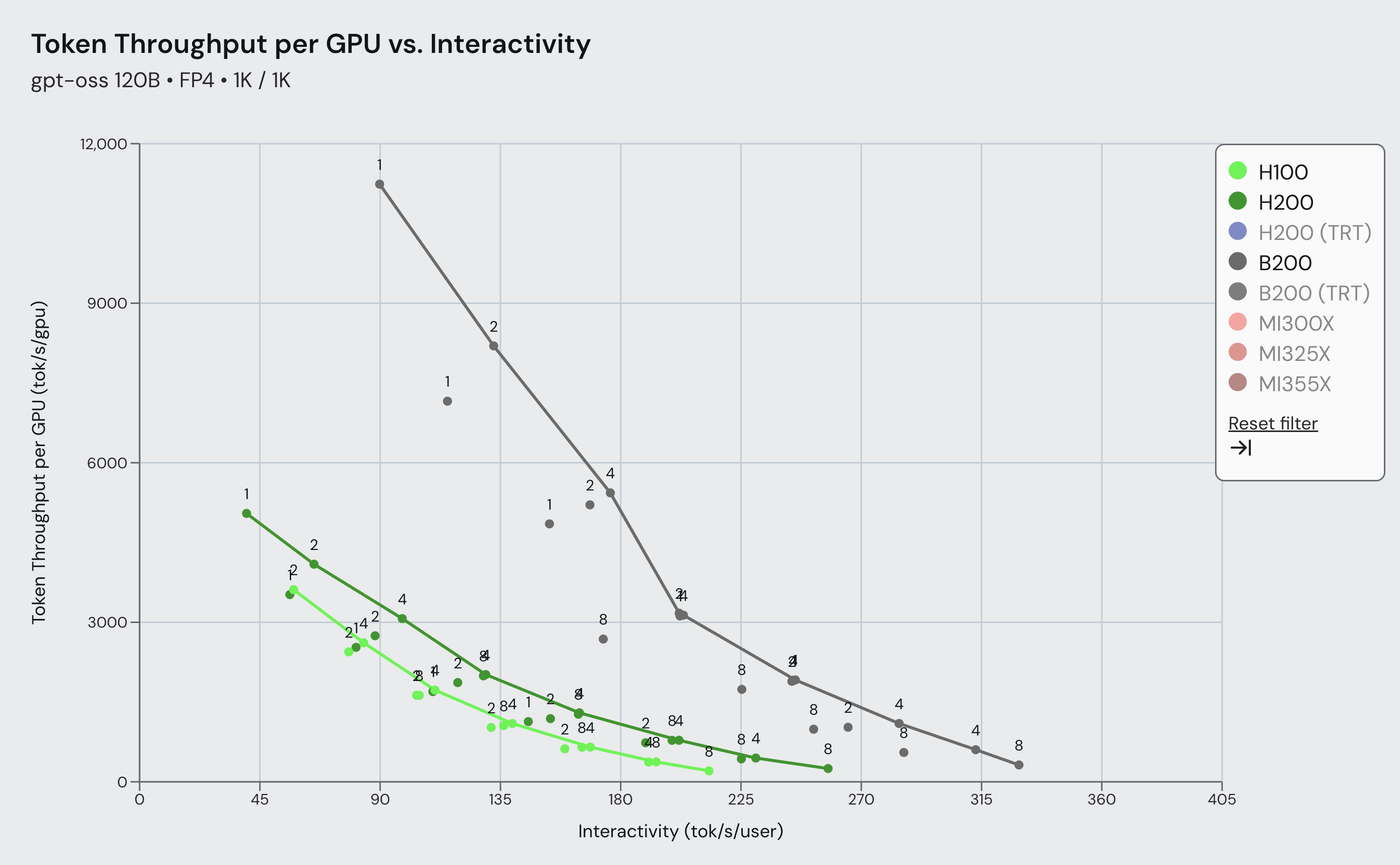
Figure 1: SemiAnalysis InferenceMax gpt-oss-120b Pareto Frontier comparing vLLM Blackwell and Hopper performance for 1k/1k ISL/OSL across a wide range of interactivity. Results show up to 4.3x more throughput using vLLM on Blackwell vs. Hopper.
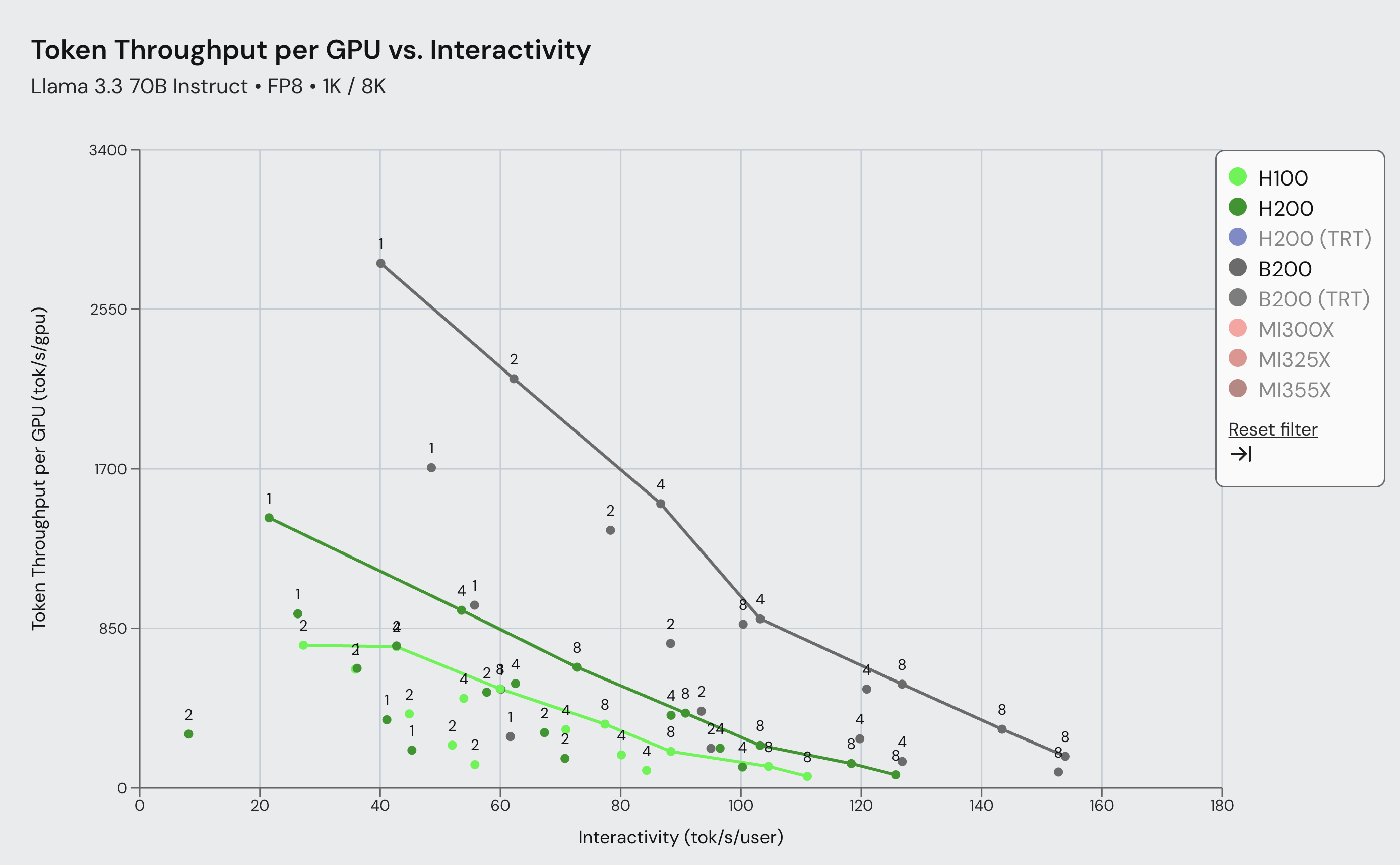
Figure 2: SemiAnalysis InferenceMax Llama 3.3 70B Pareto Frontier comparing vLLM Blackwell and Hopper performance for 1k/8k ISL/OSL across a wide range of interactivity. Results show up to 3.7x more throughput using vLLM on Blackwell vs. Hopper.
These performance gains are reproducible today using the InferenceMAX configurations provided by SemiAnalysis. It’s a testament to what optimized software can achieve when focused on extracting the most from hardware. Reaching these numbers required a broad set of optimizations in vLLM, developed in deep collaboration with NVIDIA’s engineers. We outline the most significant of those optimizations next.
vLLM Blackwell Optimizations
Enabling the above performance on Blackwell involved work at all levels of the software stack. Some optimizations improve raw kernel execution speed on the GPU, while others reduce CPU overheads or better utilize hardware features. We list the key enhancements introduced for Blackwell support so far in vLLM below:
Performance Improvements
- Faster Kernels via FlashInfer: We integrated NVIDIA’s FlashInfer library to incorporate many high-performance kernels, including FP8 attention for GQA and MLA, fast FP8 and FP4 GEMMs, MoE kernels, and fused operations. For example, we were able to combine AllReduce, RMSNorm, and quantization in a single kernel launch to significantly improve latency. Leveraging kernels from a wide breadth of NVIDIA’s software stack including CUTLASS, CuTeDSL, cuBLAS, cuDNN, and TRTLLM.
- Smarter Graph Fusions: Expanding vLLM’s torch.compile graph fusions to now include operator patterns like Attention + Output Quant and AllReduce + RMSNorm + Quant delivers fused kernel performance without manual model modification and most importantly generalizes across model architectures.
- Reduced Host Overhead with Async Scheduling:
--async-schedulingnow enables full overlap between model execution and host overheads, eliminating GPU idle time previously caused by synchronization. This fully pipelines the workload, so as one batch’s inference runs on the GPU, the next batch’s data is being set up in parallel.
Usability Improvements
- Automatic Quantization and Backend Selection: vLLM automatically detects if a model is using quantization to select the right backend and will selects the optimal attention backend for your GPU. For example on Blackwell, vLLM will choose the FlashInfer-based attention (incorporating NVIDIA’s TensorRT-LLM kernels) when available, or fall back to FlashAttention as needed - no manual flags or environment tweaks needed.
- Autotuning for FlashInfer GEMM and MoE: Because the ideal kernel implementation can depend greatly on batch sizes and sequence lengths, we added an autotuning mechanism to vLLM’s GPU runner. During startup, FlashInfer will undergo automatic tactic selection by benchmarking and selecting kernels, ensuring peak performance even with varying ISL/OSL during inference.
- Quick Start Recipes for Easy Optimized Deployment: Alongside code changes, we worked with the community on quick-start configuration guides for common scenarios. Clear instructions for each model on given hardware guide users through launching servers with recommended settings, tuning parameters, validating accuracy, and benchmarking performance—simplifying setup and speeding time to results.
Ongoing Work
Each of the above optimizations was a significant project on its own, requiring close technical collaboration - and we haven’t even covered them all! Our collaboration with NVIDIA is ongoing and there are an overwhelming number of improvements on the horizon.
Looking ahead, we’re working to unlock significant throughput gains on cluster-scale inference for DeepSeek, Qwen, gpt-oss, and many more through speculative decoding and Data+Expert Parallel (DEP) configurations. With NVIDIA’s gpt-oss-120b-Eagle3-v2, which incorporates Eagle speculative decoding, we anticipate ~up to 2-3x improvement in throughput. Leveraging DEP, which takes advantage of the 1,800 GB/s low latency NVLINK GPU-to-GPU interconnect in Blackwell, we expect to unlock even further performance and much higher concurrencies than demonstrated in the InferenceMax benchmarks paving the way for even faster and more efficient inference.
Performance improvements on Blackwell are happening every day, driven by ongoing optimizations and collaboration between vLLM and NVIDIA. We’re continuously uncovering new opportunities to push the limits of the Blackwell platform for efficiency and scale.
Acknowledgements
We would like to give thanks to the many talented people in the vLLM community who worked together as a part of this effort:
- Red Hat: Michael Goin, Alexander Matveev, Lucas Wilkinson, Luka Govedič, Wentao Ye, Ilia Markov, Matt Bonanni, Varun Sundar Rabindranath, Bill Nell, Tyler Michael Smith, Robert Shaw
- NVIDIA: Po-Han Huang, Pavani Majety, Shu Wang, Elvis Chen, Zihao Ye, Duncan Moss, Kaixi Hou, Siyuan Fu, Benjamin Chislett, Xin Li, Vadim Gimpelson, Minseok Lee, Amir Samani, Elfie Guo, Lee Nau, Kushan Ahmadian, Grace Ho, Pen Chun Li
- vLLM: Chen Zhang, Yongye Zhu, Bowen Wang, Kaichao You, Simon Mo, Woosuk Kwon, Zhuohan Li
- Meta: Yang Chen, Xiaozhu Meng, Boyuan Feng, Lu Fang
You can find all InferenceMax results at http://inferencemax.ai. The code running it is open sourced at https://github.com/InferenceMAX/InferenceMAX. And their explanation of results can be found at https://newsletter.semianalysis.com/p/inferencemax-open-source-inference.
We sincerely thank the SemiAnalysis team for pushing hardware and open-source software co-design to greater heights with the intent of offering fair measurements and comparison for the community. Thank you to Kimbo Chen, Dylan Patel, and others.
We’re excited to keep refining and expanding our optimizations to unlock even greater capabilities in the weeks and months ahead!