TL;DR. Agent often calls LLMs via OpenAI‑compatible endpoints, which previously return only string-based inputs and outputs. In agent RL, this can lead to inconsistencies between training and inference due to the phenomenon we call Retokenization Drift. This phenomenon occurs because tokens are detokenized during inference and subsequently retokenized during training; the two sets of tokens may differ even though their corresponding strings are identical. Now, you can ask vLLM’s OpenAI‑compatible endpoints to return the exact token IDs for both prompts and generated responses. Pass "return_token_ids": true to /v1/chat/completions or /v1/completions and you’ll receive prompt_token_ids and token_ids alongside the regular text output. This makes agent RL robust, as no more drift will happen. This pairs perfectly with Agent Lightning, where each model call is viewed as separate update sample without stitching; just log the returned IDs via return_token_ids enabled.
Links:
- Docs: OpenAI‑compatible server
- Project to try with this feature: Agent Lightning (GitHub, docs)
Why token IDs matter for Agent RL
RL for LLMs trains on token sequences, so trainers need the exact token IDs sampled by the behavior policy. In single‑turn settings this used to be straightforward, since calling vLLM’s low‑level generate returns tokens directly.
In agent settings, most agent frameworks call OpenAI‑style chat.completions / completions. Agents prefer these APIs over raw generate because they provide the higher‑level affordances agent stacks are built around, such as chat templating & roles (system/user/assistant), tool/function calling, structured outputs, and so on. These APIs historically return strings only, which might cause problems in agent RL. Previously, stored texts must be retokenized during training, but this is unstable and less accurate in practice, due to the retokenization drift.
Symptoms you’ll see in RL: unstable learning curves (shown in the below figure), and hard‑to‑debug divergence between the data you think you optimized on vs. what the model actually sampled.
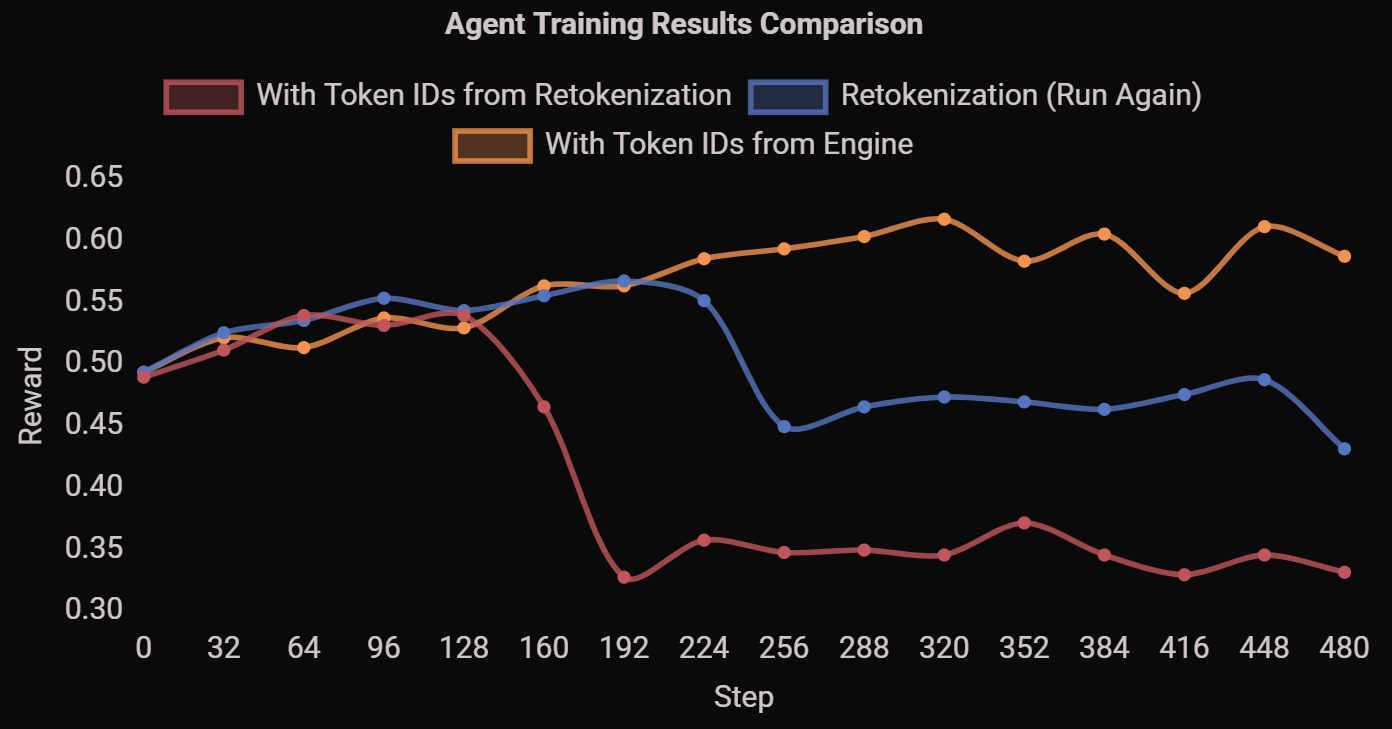
The red and blue lines are obtained with same settings (i.e., store texts and retokenization in training) and the yellow line directly use tokens from the inference engine.
The drift may caused by the following three reasons.
- Non-unique “HAVING”. In practice this shows up constantly: a word might be produced during generation as two tokens (e.g.,
H+AVING), but when you re‑tokenize the text later during training you get a different split (e.g.,HAV+ING). The text looks identical, but the IDs differ, making your learner optimizes against the wrong sequence.
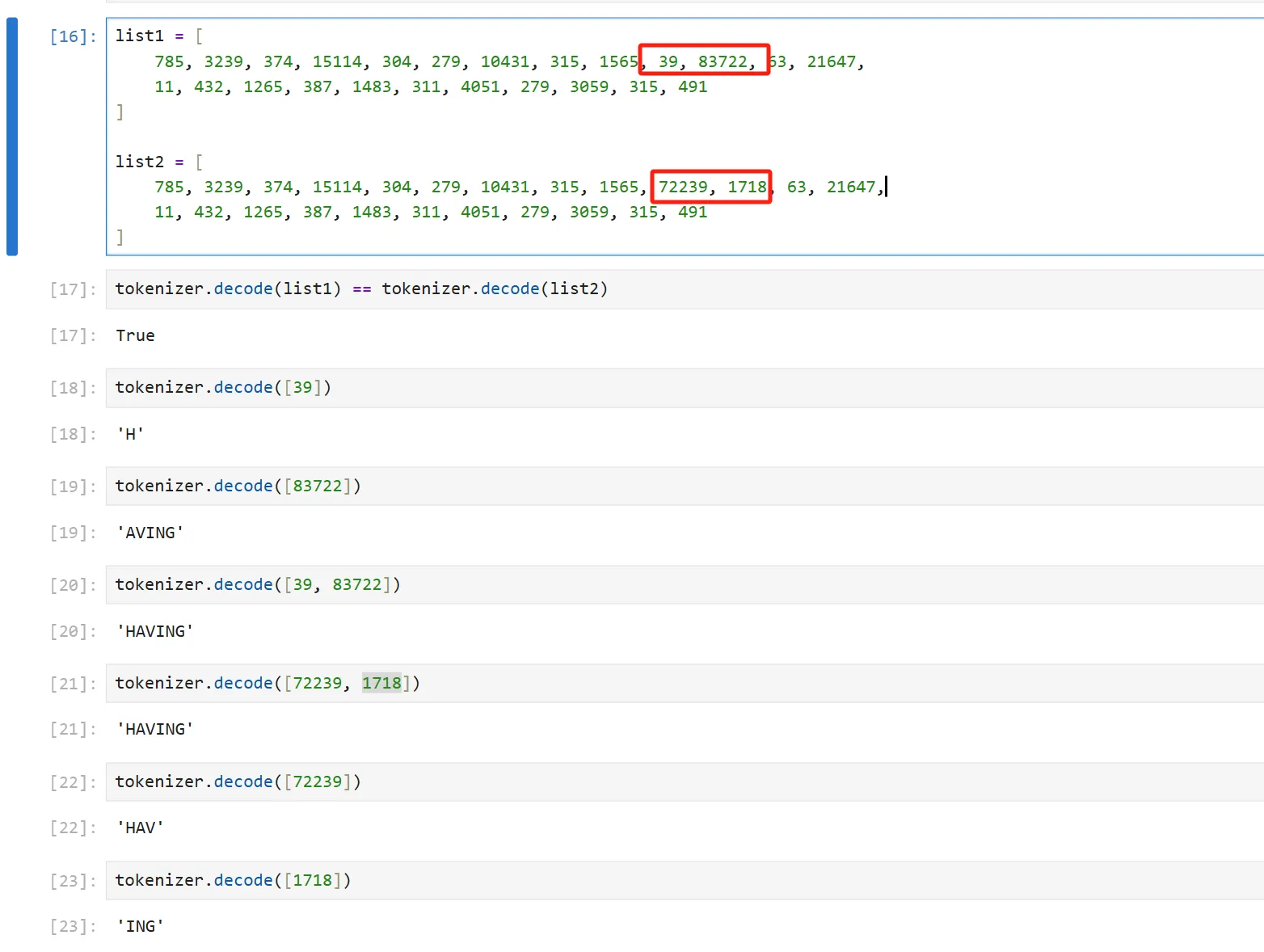
The word "HAVING" corresponds to different tokens.
- Tool-call serialization. a generated tool call text like
<tool_call>{ "name": ... }</tool_call>is parsed by tool call parser into an object that is required by chat completion API. Later, the object is rendered back to<tool_call>{ "name": ... }</tool_call>and retokenized again. Tool call parsing and re-rendering might cause changes in whitespace and formatting. In some situations, JSON errors may even be auto-corrected by the tool call parser. This masks the model’s true generation errors and preventing them from being trained away. - Chat template difference. Chat template used in different frameworks could be slightly different. For example, one single LLaMA model can work with multiple chat templates (multiple in vLLM and one in HuggingFace). When different frameworks are used in inference and training, this divergence will produce different tokens.
These three factors cause retokenization drift, and then lead to training instability, possibly because they result in the inconsistency between inference and training, and then cause off-policy RL updates. On-policy is a critical for stable RL training, and subtle changes can make big influences. The off-policy effect caused by retokenization drift is not even at the token level, and therefore cannot be corrected through token-level importance sampling.
The alternative is to save the token IDs generated by the model, as done in single-turn settings. This requires agents must communicate with the inference engine at the token level. However, most agents — especially those built with frameworks like LangChain — rely on OpenAI-compatible APIs and can’t tokenize or detokenize by themselves. See here for more discussions about this part.
Solution and new feature
A better solution is to use an OpenAI-compatible API that returns token IDs directly. The Agent Lightning and vLLM teams have collaborated to add this feature directly to vLLM core. Starting with vLLM v0.10.2, the OpenAI-compatible API includes a return_token_ids parameter, allowing token IDs to be requested alongside chat messages. When you set it to true on a request, the response includes two additional fields:
prompt_token_ids: the token IDs for the input (after any chat template processing), andtoken_ids: the token IDs generated for the completion, passed viacompletion.choices.
Everything else in the response stays OpenAI‑compatible, so existing clients keep working.
Introduction to Agent Lightning (v0.2)
In Agent Lightning (AGL for short) initial version (v0.1), we delivers a flexible training framework for ANY agent with RL. It has several core features.
- Seamless integration with existing agents with ZERO CODE CHANGE (almost)!
- Build with ANY agent framework (LangChain, OpenAI Agent SDK, Microsoft Agent Framework, …); or even WITHOUT agent framework (Python programs).
- No constraints on the input to the LLM, allowing for flexible orchestration such as summarization, multi-agent collaboration, and other complex workflows.
When Agent Lightning was first released, we implemented an instrumented vLLM server that monkey-patched vLLM’s OpenAI server to return token IDs. Now, AGL automatically adds return_token_ids to each request so the engine includes token IDs in its response. Then, with the tracing capability embedded in AGL, we automatically collect data required by the trainer side, including these token IDs.
The middleware for agent optimization
Starting from the perspective of more precise data collection, in v0.2 we have made AGL’s role in agent optimization more clear. Conceptually, Agent Lightning, or AGL, introduces a sustainable middleware layer and standardized data protocols for agent optimization, especially agent RL.
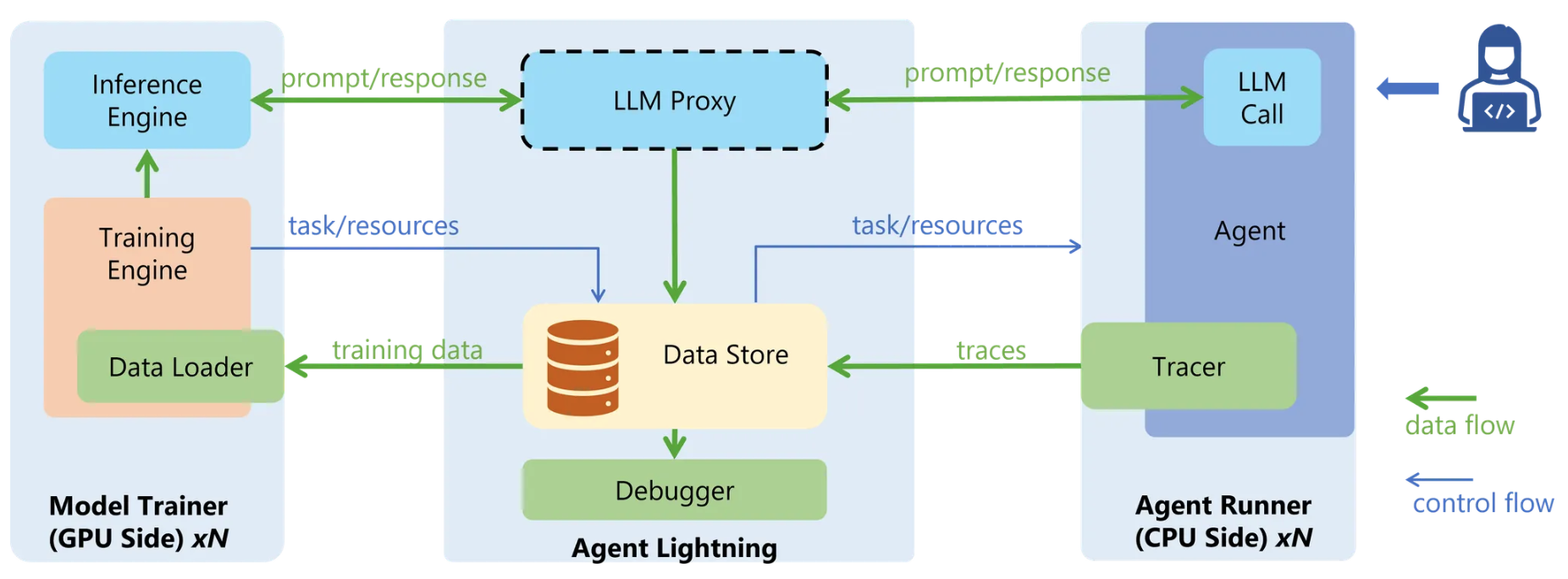
Conceptual Overview of Agent Lightning.
Agent Lightning is designed with a set of modular, interoperable components that together enable scalable and efficient agent RL. Each component plays a distinct role while communicating through standardized data protocols and well-defined interfaces.
- Agent Runner — Responsible for executing agents to accomplish assigned tasks. It receives tasks, delegates them to agents for execution, collects both results and intermediate data, and reports these back to the data store. The Agent Runner operates separately with LLM side, thus can be hosted with different resources (e.g., CPUs) and can scale horizontally to support large numbers of concurrent agent instances.
- Algorithm (Model Trainer) — Hosts the large language models (LLMs) used for inference and training. This component orchestrates the overall RL loop, including task sampling, rollout management, and model updates based on collected experience data. It typically runs on GPU resources and interacts asynchronously with the Agent Runner through the shared data protocols.
- Data Store — Serves as the central repository for managing all data exchange and storage within the Agent RL ecosystem. It provides standardized interfaces and unified data schemas to ensure interoperability among heterogeneous components. Through this design, the Algorithm and Agent Runner can communicate indirectly yet effectively, enabling flexible and scalable collaboration. For instance, using the standardized
rollouts, the Algorithm can delegate tasks asynchronously to the Agent Runner, which executes them and reports execution traces back via thespansdata structure.

The Training Loop in Agent Lightning.
Under this data-store-centric design philosophy, all agent training iterations are abstracted into two steps. The first is to collect the agent-running data (spans in AGL) and store them in the data store; the second is to retrieve the required data from the store and send them to the algorithm side for training.
This abstracted view brings several advantages. First, it offers greater algorithmic flexibility: data collection can rely on various tracers or emit customized message, making it straightforward to define different rewards or to capture any intermediate variables. On the algorithmic side, the required data can be accessed through query spans, and customized adapters enable free data transformation.
This design also supports algorithm customizations like credit assignment, auxiliary model learning using partial data, training improvement through data adjustment, and so on. Moreover, within this framework, we can extend to more kind of algorithms, like automatic prompt tuning (APO), filtering high rewards data and fit them via Unsloth.
The second major advantage of this design lies in its ability to reduce overall system complexity through modular separation, while enabling different components to utilize distinct resources and optimization strategies. An agent RL training system is inherently complex, as it leverages dynamic, environment-driven interactions to enable continual model learning from experiential data. A typical agent RL stack consists of several key components, including agent frameworks (e.g., LangChain, MCP), LLM inference engines (e.g., vLLM), and training frameworks (e.g., Megatron-LM). Without a decoupled architecture, the independence and heterogeneity of these components can lead to substantial system complexity. In contrast, a decoupled design allows the system to accommodate diverse resource requirements: for instance, the agent side may demand higher CPU capacity, whereas LLM inference and training are typically GPU-intensive. This modular structure also facilitates independent horizontal scaling for each component, improving both efficiency and maintainability.
More materials:
- Full Documents
- Birds Eye View
- Train a SQL Agent (with multi-agent orchestration) using verl
- Train a Room Selector Agent using Automatic Prompt Optimization, where prompt orchestration is powered by POML.
- Train a Math Agent (build with OpenAI Agents SDK with MCP) using Unsloth
Happy training! ⚡
Acknowledgements
We would like to express our sincere appreciation to vLLM maintainers, including Kaichao You, Nick Hill, Aaron Pham, Cyrus Leung, Robert Shaw and Simon Mo. Without their support and collaboration, this integration would not have been possible.
Agent Lightning is an open-source project from Microsoft Research. We sincerely appreciate the support from MSR for this open-source exploration. Yuge Zhang is the primary contributor to this work.